


克莱尔桑塞姆需要“峰值”的数据库停止研究人员被埋在雪崩的化学信息
克莱尔桑塞姆需要“峰值”的数据库停止研究人员被埋在雪崩的化学信息
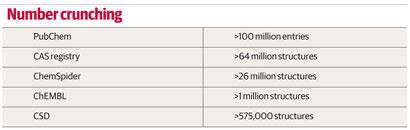
随着基因组测序成为常规,分子生物学家和数据存储一个日益严重的问题。山的语句,例如“数据”和“雪崩”数据的生物信息学文学十多年来,这个问题一样有疑问的现在在世纪之交。化学家的数据有问题,但是我们的有所不同。当然有一个庞大而指数增长的已知的化合物,但每个实体(因此每个数据库条目)相对较小。安东尼·威廉姆斯,创始人和现在的战略发展副总裁RSC的ChemSpider数据库,解释道:“Cheminformatics不-然而面对生物信息学的可伸缩性问题。完整的大多数化学数据库可以存储在硬盘上的一个相当普通的笔记本电脑或台式电脑。
但数据库,尤其是指数增长的,是昂贵的。挤在公共财政向一个方向,越来越期待科学数据应该是免费的——或者至少便宜访问——拉,不容易想出可持续模型数据访问。错误的持久性化学数据库和他们的易用性也实际问题。
开始时
化学数据库的时代始于1907年,当时美国化学学会启动,开始在纸上,最后在网上,其化学文摘服务(CAS)化学文献目录。它的数据库条目超过6400万种化合物。60一百万大院,一个潜在的抗病毒药物记录在2011年,两年之后才被撞的50一百万的里程碑——展示小说分子合成速度的加快。
三维结构的小分子(中小)——即化学而不是生化结构——在剑桥结构数据库(CSD)。在剑桥大学成立于1965年,英国的第一版CSD又一本书,包含引用和表几百化学结构的原子坐标。

启动第一个软件包搜索CSD(软件)的追求在1980年代是一个相当革命,杰森·科尔说,剑桥晶体数据中心副主任(CCDC),维护数据库。这有我们今天会承认作为一个图形用户界面,你可以画子结构和搜索。今天,数据库包含超过575000结构,而且还适合在一个硬盘。我们的完整的数据库占用100 gb,这是小在生物信息学方面,但是我们发送给客户的是5 gb的,”科尔说。CSD使用遗留数据格式,继承所需的那些早期的搜索算法。我们正在重写我们的数据库格式适合21世纪。这将使我们的搜索引擎更快,功能更强大,也更容易使用,但它是一种单调的项目放在次要地位多年来,”科尔承认。
空间的混乱
如果记录在所有不同的化学数据库结合,删除重复的——可能是一个不可能完成的任务——结果将包含几个亿的条目。很有益的化学空间这是问什么分数。一些知名的化学家预测变化多端的数字可能的化合物;瑞士伯尔尼大学的jean - louis Reymond,提供最可能的估计。他的小组正试图回答这个问题“有多少小分子可能吗?通过建立一系列的数据库称为GDB生成数据库(分子)。最新的变体,GDB-13,包含所有化学可行和13 C的原子结构,N, O,年代和Cl。Reymond推断的数量达到最大可能的药物如分子,分子质量约500年,将产生约1018-10年19约翰Overington说分子,计算化学生物学组长在剑桥附近的欧洲生物信息学研究所,英国。我们对100亿年有记录的。

大多数数据库,除了CSD,只有保存实验数据的二维结构和立体化学分子。这种2 d数据通常表示为简单的文本字符串,叫做微笑(简化分子输入行条目规范)符号——帮助存储和搜索。这种类型的表示法是非常宝贵的,但也会导致混乱。并不是所有的研究小组使用相同的微笑诠释和附加组件,允许不同表示相同的复合渗透互联网。相反,很难展示互变异构体是可互换的形式相同的化合物。
ChemSpider的威廉姆斯告诉一件轶事,表明微笑格式的限制。如果你在PubChem寻找钻石,其中一个最大和最著名的化学数据库,您将检索条目甲烷,“他说。这似乎很奇怪,但是解释很简单:甲烷的微笑表示,CH4,是钻石或C -一样,事实上,石墨。“国际纯粹与应用化学联合会介绍了InChI(国际化学标识符)表示的化合物作为后续,而不是替代标准的微笑,以减少这些差异(而不是消除)。
给我钱
资金和数据访问的相关问题是房间里的大象在任何讨论的科学数据库。几十年前几乎每个数据库是政府资助的。仍有许多完全公共资金资助的数据库,尤其是来自美国政府和欧盟消息人士,但紧缩措施,增加数据库的大小和复杂性的蚕食这个模型从相反的方面。科尔CSD讲的许多社区里当他说‘授予机构倾向于认为资金的项目,而不是资金资源,所以它更容易得到钱建立一个数据库维护它。此外,与融资经常提供最多三年,数据库可能经常被置于危险的境地。
Overington欧洲生物信息学研究所的教授和他的团队正在建立一个免费公开资助2 d的数据库结构和药物活性分子的活动。他们ChEMBL数据库是由英国慈善威康信托基金会,大约100万种化合物,包含数据,主要从文献中提取。我们所有的数据都来自免费资源,Overington说。”当我们专注于药物化学与生物活性化合物,大多数都是相当简单的有机分子,”他解释说。
诚然短暂历史的一个流行的数据库,ChemSpider,表明它可以设置数据库以可持续的方式没有任何初始资金。ChemSpider成立于2007年,威廉姆斯-然后首席科学官先进化学发展(ACD /实验室)在多伦多,加拿大,最初作为爱好项目与朋友,与视觉的拖网互联网化学数据提取到一个数据库中。拖网捕鱼时也没能实现,ChemSpider数据库上线的第一个版本在2008年年初和RSC 2009年5月收购。它现在包含超过2600万个条目,化学社区帮助其扩张和管理使用的众包模式。

利用网络资源来建立这个数据库显示显著的错误数量在著名的化工资源,包括5个化合价的碳原子和明确mis-associations化学名称和结构。这使得威廉姆斯任务来提高数据的质量和教育社区,数据源是最可靠的。他在ChemConnector博客使用问卷调查的8个广泛使用的公共资源(包括他自己)是最可信的,和测试相同的资源错误使用200常见的小分子药物的结构。他发现每个数据库中的错误,包括三个严重的ChemSpider(立即纠正使用web接口提供给所有用户)。最高的数据库的信任值是ChemSpider(也许毫不奇怪,因为调查是通过他的博客进行推广)和PubChem。有趣的是,他承认,他本人不会报告,他总是值得信赖的数据资源。
缺乏绝对的信任反映了理解,任何数据库不可能100%甚至99.99%可靠。Overington同意数据库总是包含错误,但认为这是在实践中,而不是什么问题了。有一个层次结构的表征错误及其后续影响使用,化学家们通常视图中的错误公式是最重要的,其次是分子图形、立体化学、盐形式最后物理/晶体形式。不同的技术对不同的错误类型,错误是依赖于上下文的影响——例如,药物产品,水晶形式可以主导产品属性,”他说。
失去了摇钱树
相对较少的化学数据库的CSD是故意走商业路线来融资。它最初是由研究资助,但1980年代末其管理团队与格兰特的永无止境的循环应用程序变得沮丧和关注资源的长期可持续性。相信——正确,数据库包含足够的信息对医学相关化合物的兴趣,他们建立了中国疾控中心作为一个非盈利的公司。超过80%的收入用于工业用户提供的数据库和一个单独的软件公司中国疾控中心的活动。
但制药行业正在发生变化。直到最近,许多科学家也将其视为一个摇钱树,能够提供资源和补贴贫困学术界设施。但随着每注册药品成本失控,两个行业之间的界限是模糊的。在最近的一篇社论药物发现今天,巴里Bunin和肖恩·伯林盖姆协作药物发现的郑伊健,我们讨论如何与公共部门的合作,并与学者和池数据竞争对手,可以帮助早期药物发现。公共领域数据库如PubChem和ChemSpider引用在一系列的创新工具,提高药物发现的效率”。
协作药物发现的网站允许用户存储的记录结构活动,药代动力学和其他数据的“金库”。Bunin解释了公司独特的协同工作方式:“用户可以选择分区数据任何他们想要的,也许一些私人和分享其他记录在他们的组织,和一群合作者或整个社区。其商业模式作为一个营利性公司强大的社会关注,持有授予盖茨基金会和其他的工作——被忽视的热带疾病也是不寻常的。这个例子是进一步证明化学社区仍在寻找创新的方法来提供访问的挑战和准确的数据即使在困难的时期。
克莱尔桑塞姆是一个基于科学作家在剑桥,英国
进一步的阅读
B Bunin和郑伊健,药物发现今天,2011,16,643 (DOI: 10.1016 / j.drudis.2011.06.012)
也感兴趣的
![]() ChemConnector博客
ChemConnector博客
化学帮助创建连接





还没有评论