
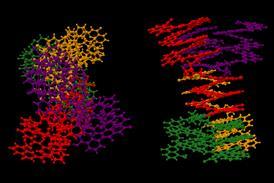




5000纳米实验教算法预测的结果反应抑制剂的存在
棘手的交叉耦合反应的产量现在可以准确预测的计算机程序,教自己如何解决这个棘手的问题。算法的关键技术是数据从成千上万的小规模训练反应。大的目标,这是一个很小的一步,是能够预测新基板没有反应的性能实验,”解释道阿比盖尔道尔从普林斯顿大学,领导从默克公司与斯宾塞·德雷尔共同努力。
机器学习已经帮助科学家探索化学空间,寻找新的合成途径和预测反应的结果。然而,产量预测软件仍然经常出错的时候。这是因为数据算法必须与许多团体多年来收集的反应参数,往往是不一致的和不完整的。反应不学习,例如,通常没有报告。
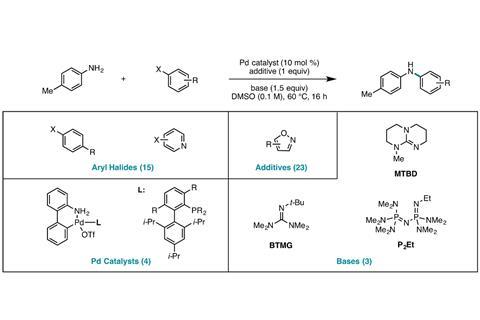
为了克服这个问题,我们团队创建了一个定制的数据库近5000 Buchwald-Hartwig耦合,palladium-catalysed反应使碳和氮之间的一条纽带。一个异恶唑-抑制交叉耦合的一个杂环是添加到每个反应。尽管增加了困难,该算法Princeton-Merck团队训练在这个数据可以正确地预测收益率在一个较小的比例,接近实验误差。
5000年开展实验将人类的化学家几个月,甚至几年,柯南道尔和德雷尔的帮助默克公司的高通量平台一天,可以执行1500年摩尔反应。随机森林算法然后美联储3000年的结果的反应以及计算计算参数,如HOMO和LUMO能量——每个试剂。
森林通过构建决策树学习算法。这些树可能是/否的问题像“收益率提高如果芳基卤化物的LUMO能量上升?“,”道尔解释道。对于每个问题,程序添加一个新的分支;输出是成千上万的决策树的平均值。
看到算法的预测精度变化的美联储更多的数据学习,团队尝试训练只有230实验。虽然失去了一些模型的预测能力,测量其准确性变化相对较少。“我认为强大的模型性能与稀疏数据集是特别有趣,因为大多数组织很难屏幕超过4600的反应,”说娜塔莉Fey布里斯托尔大学的计算化学家英国。
然而,发现背后的推理算法的预测往往仍然是具有挑战性的。”作者指出,模型可能非常难以解释,“异常兴奋的说。虽然这种类型的“黑盒”法”很可能是如果重点是反应工作,但在学术上是不满意的,她补充道。
然而,结果真的是有前途的,说安娜Gambin计算大学的分子生物学家,华沙,波兰。“从纸是伟大的消息,如果足够的可用性预测,反应效率的分类是可行的。
团队希望能教他们如何处理算法结构复杂的化合物。的基板在我们的研究中都是平的,”道尔指出。当你得到三维结构,这将带来额外的挑战,能够描述基质之间的差异。
引用
D T Ahneman等,科学,2018,DOI:10.1126 / science.aar5169






还没有评论