
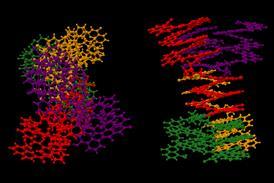




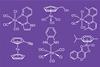
第一次,小弦被用来编码氨基酸的巨大的超过40000种化合物的化学库。由于这些肽库,研究人员能够识别许多癌症药物候选。
化学库的概念是在药物发现流行。这依赖于两个关键组件——编码和解码信息,”解释共同第一作者Grob娜塔莉来自美国麻省理工学院。它像条形码:附加了独特的“标签”的一系列小分子,研究人员之前调查他们的亲和力的蛋白质与已知的疾病相关。然后,最好的绑定是通过阅读标签识别。通常,化学家标记化合物与DNA片段,使快速而简单的分离和审讯的图书馆。但是DNA限制的可能性,主要是因为敏感性和不相容的核苷酸与某些化学品和催化剂,如强酸、过渡金属,甚至激进分子。
然而肽,可以容忍更大范围的条件,包括交叉耦合使他们DNA的极好选择。在此之上改进反应兼容性,标签与肽可以加快解码过程,Grob解释道。我们解码标签使用质谱,而DNA标记需要酶反应和像PCR扩增方法,”她说。
基督教海因斯肽EPFL在瑞士,专家说,这一技术的巨大优势[s]的化学和结构不同的图书馆的建设。强劲的阻力的主要,这是保护肽的化学条件下,允许生产许多不同的分子和构建块。据我所知,这是第一次肽[工作]编码和筛选小分子库,”他补充道。此外,固相合成[方法]可以允许一个自动化生产。
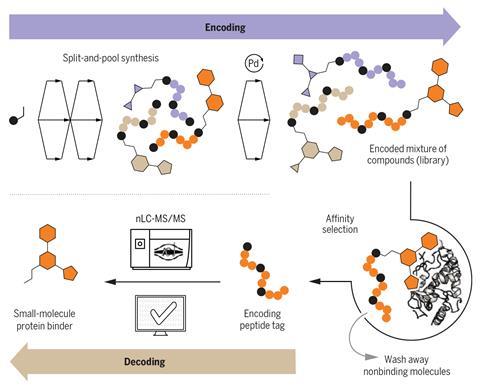
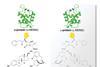
然而,这个过程仍手册。然而,我们合成完整的图书馆在不到一周的时间,“说共同第一作者西蒙Rossler。固相合成不像解决方案,我们的反应非常快,不需要优化方法进行了净化,”他解释说。他们遵循所谓的splitting-pool在组合化学策略。图书馆的合成形式有许多共享的“家谱”分支结构的步骤。我们花大量的时间考虑试剂,合成肽,而不是“他的笑话。
尼娜Hartrampf肽和苏黎世大学基础有机化学专家,瑞士,解释说的起始分子图书馆是固定在树脂支连接器连接氨基酸的条形码和小分子。两端的反应然后迭代执行,”她说。“生成库…树脂分为小的部分,然后区别对待。每个部分是functionalised不同小分子片段,然后用相应的氨基酸编码。后每一对反应- functionalisation和编码整个树脂再次重组和分裂,进行下一组;这是如何生成的序列空间。由于合成的坚定支持和高收益率反应,反应结果没有净化干净。挑战真的有[多肽的编码和解码,她补充道。
与相关蛋白亲和力的研究后,团队提取物的混合物best-binding候选人和正交氧化条件下释放肽标签。不同的标签是通过质谱仪然后分离并运行。”然后,有软件,将光谱直接转换成肽序列,”她补充道。此外,我们还开发了一个Python项目过程数据,读取结果序列和识别微笑一系列相应的化学成分在图书馆,就像一个电子词典,“Rossler说。
信息容量是肽的另一个关键优势——由四个字母构成,DNA字母相当有限。麻省理工学院的团队使用字符串的八个编码氨基酸从16个字母,天然和非天然的单体。理论上讲,这个十六进制代码可以传达4 gb的数据,超过43亿个可能的化学代码从八个不同的根,最多65000使用相同数量的核苷酸。此外,其他非天然的氨基酸可能进一步扩大化学代码,只要他们有不同的分子质量。我们可以很容易的两倍大小的字母包括氨基酸的氘类似物使用,“Grob说。
引用
SL Rossler Grob NM等,科学,2023,379年eadfl354 (DOI:10.1126 / science.adf1354)



还没有评论